2019/06/08 14:04

|
「SRE サイトリライアビリティエンジニアリング」 を読んだ
|
#### 📕今回読んだ本
<a href="https://www.amazon.co.jp/SRE-%E3%82%B5%E3%82%A4%E3%83%88%E3%83%AA%E3%83%A9%E3%82%A4%E3%82%A2%E3%83%93%E3%83%AA%E3%83%86%E3%82%A3%E3%82%A8%E3%83%B3%E3%82%B8%E3%83%8B%E3%82%A2%E3%83%AA%E3%83%B3%E3%82%B0-%E2%80%95Google%E3%81%AE%E4%BF%A1%E9%A0%BC%E6%80%A7%E3%82%92%E6%94%AF%E3%81%88%E3%82%8B%E3%82%A8%E3%83%B3%E3%82%B8%E3%83%8B%E3%82%A2%E3%83%AA%E3%83%B3%E3%82%B0%E3%83%81%E3%83%BC%E3%83%A0-%E6%BE%A4%E7%94%B0-%E6%AD%A6%E7%94%B7/dp/4873117917/ref=as_li_ss_il?__mk_ja_JP=%E3%82%AB%E3%82%BF%E3%82%AB%E3%83%8A&crid=1O3PXN8CL2GM3&keywords=site+reliability+engineering&qid=1559969318&s=gateway&sprefix=site+re,aps,233&sr=8-1&linkCode=li3&tag=&linkId=c641017d414f8f2e46be43eb5f318303&language=ja_JP" target="_blank"><img border="0" src="//ws-fe.amazon-adsystem.com/widgets/q?_encoding=UTF8&ASIN=4873117917&Format=_SL250_&ID=AsinImage&MarketPlace=JP&ServiceVersion=20070822&WS=1&tag=&language=ja_JP" ></a><img src="https://ir-jp.amazon-adsystem.com/e/ir?t=&language=ja_JP&l=li3&o=9&a=4873117917" width="1" height="1" border="0" alt="" style="border:none !important; margin:0px !important;" />
ひよっこエンジニアの自分でも「開発だけできててもだめだるぉぅ!?」と言われる年齢になってきたので、ちょっと古いですがSRE本とも言われるこの本を読んでいます。

…それにしてもこの本、分厚い。500ページ超かつ高密度な内容なので、1~3章は必読としてその他は掻い摘んで読むこととします。
#### 1章 イントロダクション
##### 1.1 サービス管理へのシステム管理者のアプローチ
> 歴史的に企業は複雑なコンピューティングシステムを動作させるために、システム管理者を雇用してきました。
シスアドとも表現される。これは一般的な開発者とは異なる文脈で語られるものであり、下記のような説明が書かれている。
> 開発者とシスアドは「開発」すなわち「dev」と、「運用」すなわち「ops」という別々のチームに分けることになります。
自分は開発をメインでしておりますし、社内の役割分担も(改善されている最中だが)devとopsは明確に別々の作業を別れて仕事をしています。
こういった役割分担の弊害として、両チームが異なる目標設定をしているため、 *devチームはユーザに新しい機能を提供することを目標* とする。一方で *opsチームはサービスの安定稼働が絶対目標* となります。
殆どのサービス障害は何らかの変更や機能のローンチによるユーザトラフィック増によって引き起こされるものなので、これらのチームの目標は基本的に対立関係となります。
##### 1.2 サービス管理へのGoogleのアプローチ:サイトリライアビリティエンジニアリング
このような対立する問題にGoogleは下記のようなアプローチを取る。
> Googleのサイトリライアビリティエンジニアリングチームは、ソフトウェアエンジニアを採用することを注力し、採用したエンジニアにサービスを運用させ、従来であればシスアドによってしばしば手作業で行われていたであろう作業を遂行するシステムを構築させています。
つまり、監視・デプロイ専門家ではなくソフトウェアエンジニアにその作業をさせることで、システム化・自動化も実現することを狙っているのでしょう。
このため、SREに対してオンコールなどの「運用業務」は *50%以下* にするよう、上限を求めているようです。この上限により、SREが本来行うべきシステム化・自動化の時間を十分に確保できているということ。
##### 1.3 SREの信条
実際にGoogleには、SREに対して50%を超える運用負荷がかかるサービスは、 **開発者に差し戻しにするというフロー** がある模様。本にこのことはさらっと書いているが、これが実現されている組織がすごい。
少し飛んで "5章 トイルの撲滅" で説明されている内容では、運用作業のことを *トイル* (= サービスを動作させるために必要な作業で、手作業で繰り返し行われるため自動化可能な作業のこと) について話されています。
> 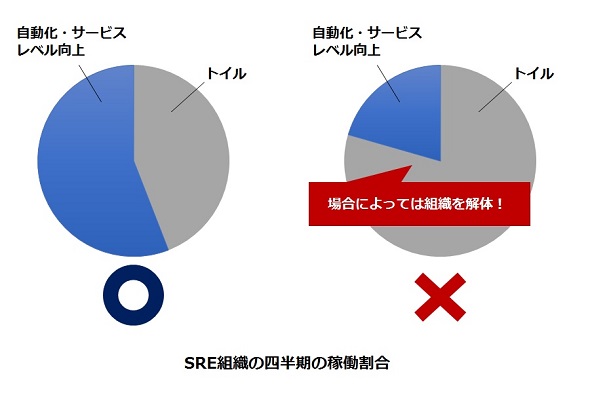
> [IT media](https://www.google.com/url?sa=i&source=images&cd=&cad=rja&uact=8&ved=2ahUKEwiblOX6m9niAhXRaN4KHeQmCeUQjhx6BAgBEAM&url=https%3A%2F%2Fwww.itmedia.co.jp%2Fenterprise%2Farticles%2F1803%2F19%2Fnews016.html&psig=AOvVaw2fWGP-WSHQnMYfST0vYPNB&ust=1560060374437122)
ここまで読んでみると、なんとなくSREを設置していく目的と理由が見えてきました。
開発側が開発プロセスを改善していく方向ととても良く似た方法で、運用側がプロダクションサービスの安定性も効率化していくようなイメージができますが、これは組織的にサポートして初めて実現できるようなものであるようにも思えます。
次章からは本格的にどう実践していくかが書かれている模様ですね。
#### 2章 SREの観点から見たGoogleのプロダクション環境
Googleのサービスは多くの独自プロトコル (といっても殆どがオープンソースとなっている気もしますが) の通信・インフラによって最適化が実現されている、という説明の章。
ハードウェアに依存しないサーバアプリケーションをデプロイし、内部通信はprotocol buffer・・・など
> 
> [CODOING](https://zhuanlan.zhihu.com/p/22354002)
基本的にこの章は以降のgoogleがどのようにサービスを効率的に運用しているかの説明のために、同社の社内事情や前提知識を説明している章のように見える。
よって、わからなかった場合に適宜見るくらいで読み飛ばしても良い気がしました。
#### 3章 リスクの受容
> 「3章 リスクの受容」は「SREの仕事とはどういうものか」、そして「なぜこのような仕事をするのか」について幅広い検知を得たい方にとっては、最重要となる必読の章です。
おそらく、この章がSREのKPIを決める上で一番重要な内容であると思われます。
##### 3.1 リスク管理
システムの可用性は最重要。だが、99%の可用性のシステムを99.9%にするコストが現在の100倍かかるなら取り組むべきでない。
また、 99%の可用性のスマートフォンで動作するWebサービスに99.99%の可用性は必要ない。
など **必要以上に信頼性を高めようとしない** ようにすべき。
##### 3.2 サービスリスクの計測
$$ 可用性 =\frac{成功したリクエスト数}{総リクエスト数}$$
グローバルに展開しているサービスにおいては時間的な可用性のメトリクス化にはあまり意味がないので、サービスのリクエストの成功率を指標とすべき。
Web APIの監視の場合、4xx/5xx エラーレスポンスの数をリアルタイムに計測しているだけだと、相対的にエラーが増加したときに問題修正に当たるということしか行われないため、ここで書かれている計測が達成できているとは言えないです。
##### 3.3 サービスリスクの許容度
仕事柄として「コンシューマーサービス」を前提として考えてみる。
リスク許容度を定義するのは *プロダクトマネージャー* が適任である。リスク許容度によってコストも変動してくるので、かなり開発・運用の深いところまでプロダクトマネージャーと相談するということになります。
##### 3.4 エラーバジェットの活用
*エラーバジェット* は許容される (1-可用性) をバジェット(予算)として使い切ることができるという考えです。
これをSREは開発成果物のリリース判定に用いることができます。
(たとえば前期までのエラーバジェット利用が予定より超過している場合はそのリリースを遅らせることができるなど)
#### (長いので)to be continued...

